XPC: Architectural Support for Secure and Efficient Cross Process Call
Published:
This post is the reading notes and building process of XPC: Architectural Support for Secure and Efficient Cross Process Call
Motivation
- Tradition IPC remains critical for microkernel yet inefficient
- SQLite’s 18% - 39% time is spent on IPC
- Most of the cycles of an IPC are spent on domain switching and message copying
- domain switching includes: context saving/restoring, capability checking and other IPC logics
- sending messages: time of check to time of use attack, TLB shootdown and other costly stuff
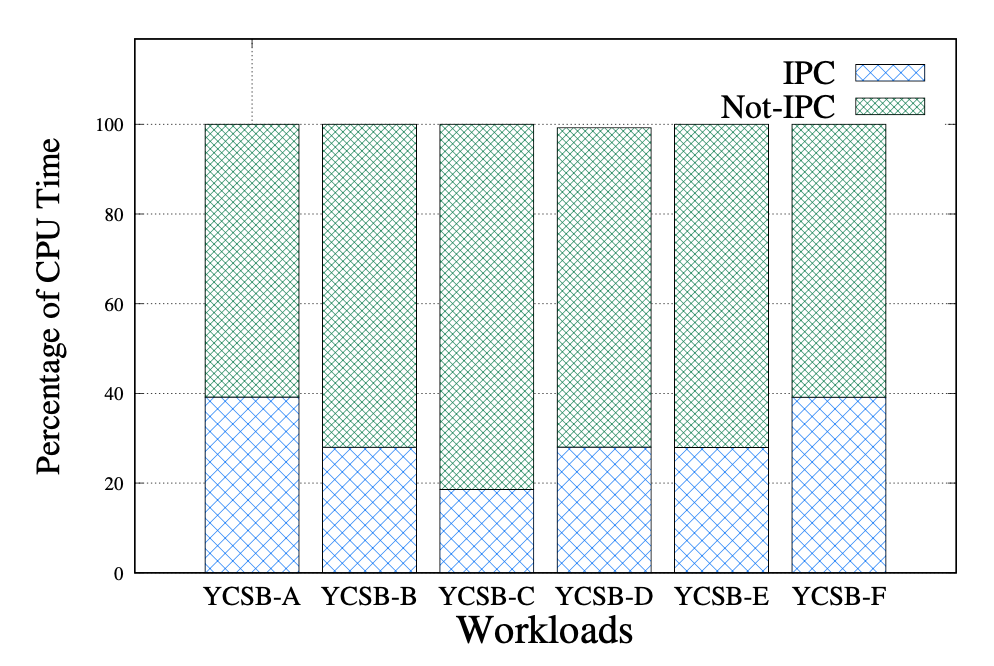
IPC occupies much of the CPU time (SQLite3 on seL4 on SiFive U500)
IPC in Zircon
Most system components run in userland. The components interact with each other with IPC.
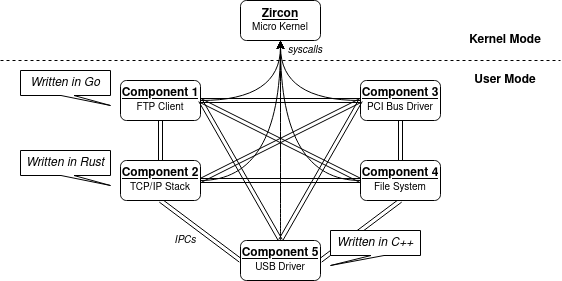
Fuchsia's IPC usage
Namespace in Fuchsia
- Each process has its own virtual filesystem, called a namespace
- The namespace contains objects, which can be files, services, devices
- These objects are ordered in a hierarchy, and accessible using file paths with the usual POSIX functions such as open()
- The kernel has no understanding of the namespace, of its hierarchy, and of its objects. The only thing the kernel is aware of, is handles.
Fuchsia’s Security Policies
- Fuchsia uses ASLR (mandatory for userland), DEP, SafeStack, ShadowCallStack, AutoVarInit. The Zircon kernel is compiled with all of that by default.
- Fuchsia has overloaded some basic programming model to prevent errors
- e.g.
[]in c++ will face mandatory range checks
- e.g.
Why IPC is so slow
- Trap & Restore
- Save the caller’s context and switch to callee’s context
- IPC Logic
- Priority and capability check
- Process Switch
- Memory access (user context, capabilities and scheduling queue)
- Message Transfer
- zero-copy does not cover all circumstances

Clock Cycles consumed by different phase of IPC
What is XPC
- An hardware-assisted OS primitive
- It has 4 goals: - direct switching without trapping to kernel - secure zero-copying for message passing
- easy integration with existing kernels - minimal hardware modifications
How XPC Works
- Hardware abstraction,
x-entryandxcall-cap- Each
x-entryhas its own ID xcall-capfor access control
- Each
- New instructions that allow user-level code to directly switch accross processes
- New AS mapping mechanism
- Support ownership transfer
- One owner of the message at any time
- Keep semantic of synchronous IPC
- Zircon use asynchronous IPC to simulate synchronous IPC
- Improve the throughput of IPC with relay-seg mechanism
- Easier for multi-threaded applications because of migrating thread model
Design 1: XPC Engine
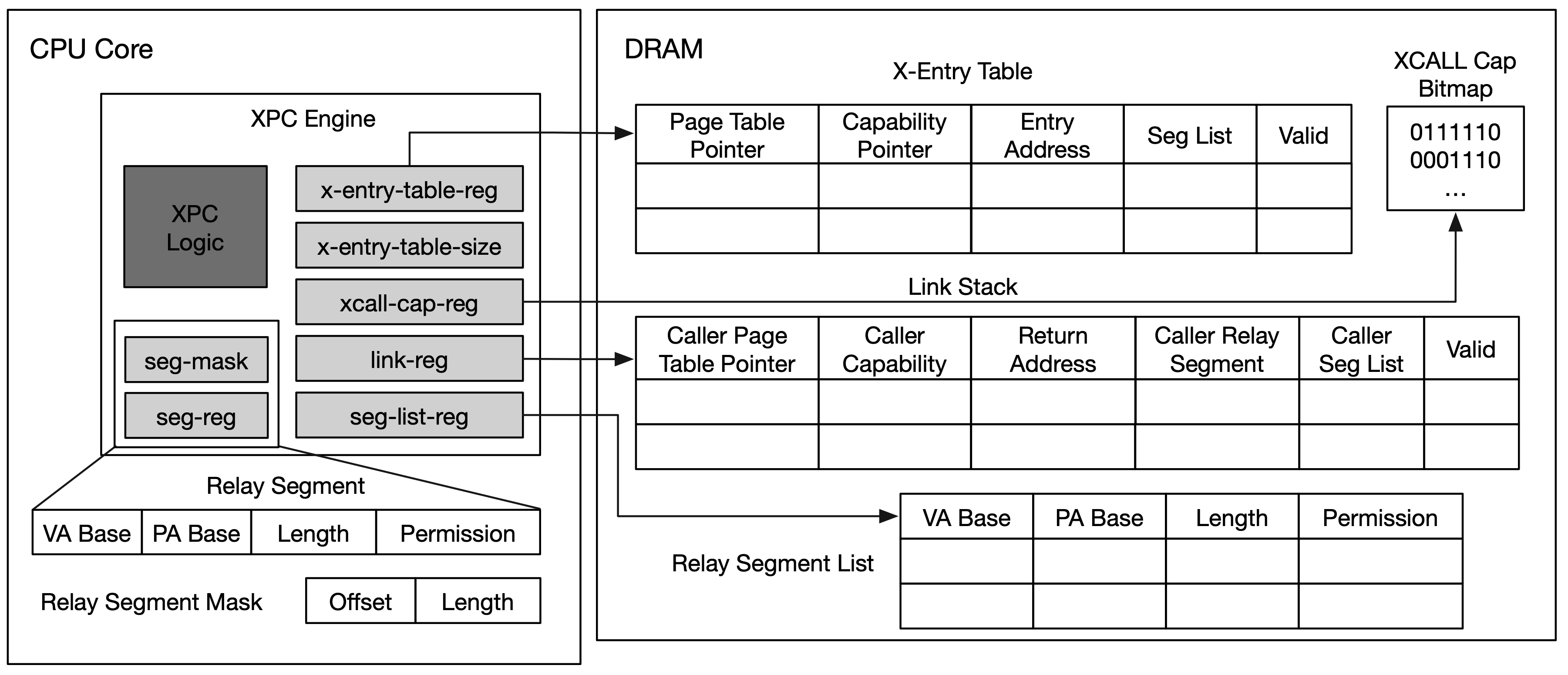
XPC-engine
- XPC Engine is the hardware support for two new primitives:
x-entryandxcall-cap - An
x-entryis bounded with a procedure that can be invoked by other processes- A process can create mutliple
x-entries - All the
x-entriesare stored in anx-entry-table - A caller needs an
xcall-capto invoke anx-entry, this record the IPC capabilities of each x-entry x-call #regwhere#regrecords anx-entryindex
- A process can create mutliple
Design 2: Relay Segment
Design 3: Programming Model
Support For Microkernels
- Capability Calculation
- Split Thread State
Evaluation
- Benchmark: 5x - 141x for existing microkernels
- Real Application: 1.6x - 12x (SQLite, HTTP Web Server)
- Hardware Cost: 1.99% LUT overhead